课程报告:Dijkstra 算法与大数据应用
课程:《数据科学与大数据技术导论》
班级:25 数据科学与大数据技术(单招)
学号:25131129
姓名:周泓霖
引言
图论作为离散数学的重要分支,在计算机科学中具有广泛应用,尤其在网络分析、路径规划、社交网络挖掘、交通调度等领域中发挥着关键作用。其中,最短路算法是图论中经典且基础的问题求解工具,例如 Dijkstra 算法、Bellman-Ford 算法和 Floyd-Warshall 算法。
Dijkstra 算法由艾兹格·迪杰斯特拉提出,常用于解决非负权图的单源最短路径问题。它以贪心思想为基础,通过不断选取当前距离源点最近且尚未确定最短路的顶点,并利用该顶点更新其他相邻顶点的距离,最终求出源点到图中各顶点的最短路径。
本文将围绕图的基本概念、图的存储方式、贪心算法思想、Dijkstra 算法原理、算法复杂度以及其在大数据中的应用展开说明。
一、图的概念及存储
1. 图的概念
在计算机科学中,图(Graph)是一种用于表示物体与物体之间关系的数据结构。一个图通常由两个集合构成:
- 顶点(Vertex):表示研究对象或实体;
- 边(Edge):表示顶点之间的关系。
一条边连接两个顶点,可以是有方向的,也可以是无方向的。若边带有方向,则称为有向图;若边没有方向,则称为无向图。此外,边还可以带有权重(Weight),权重通常表示距离、成本、时间或关系强度等。在最短路算法中,权重一般表示两个顶点之间的距离或代价。
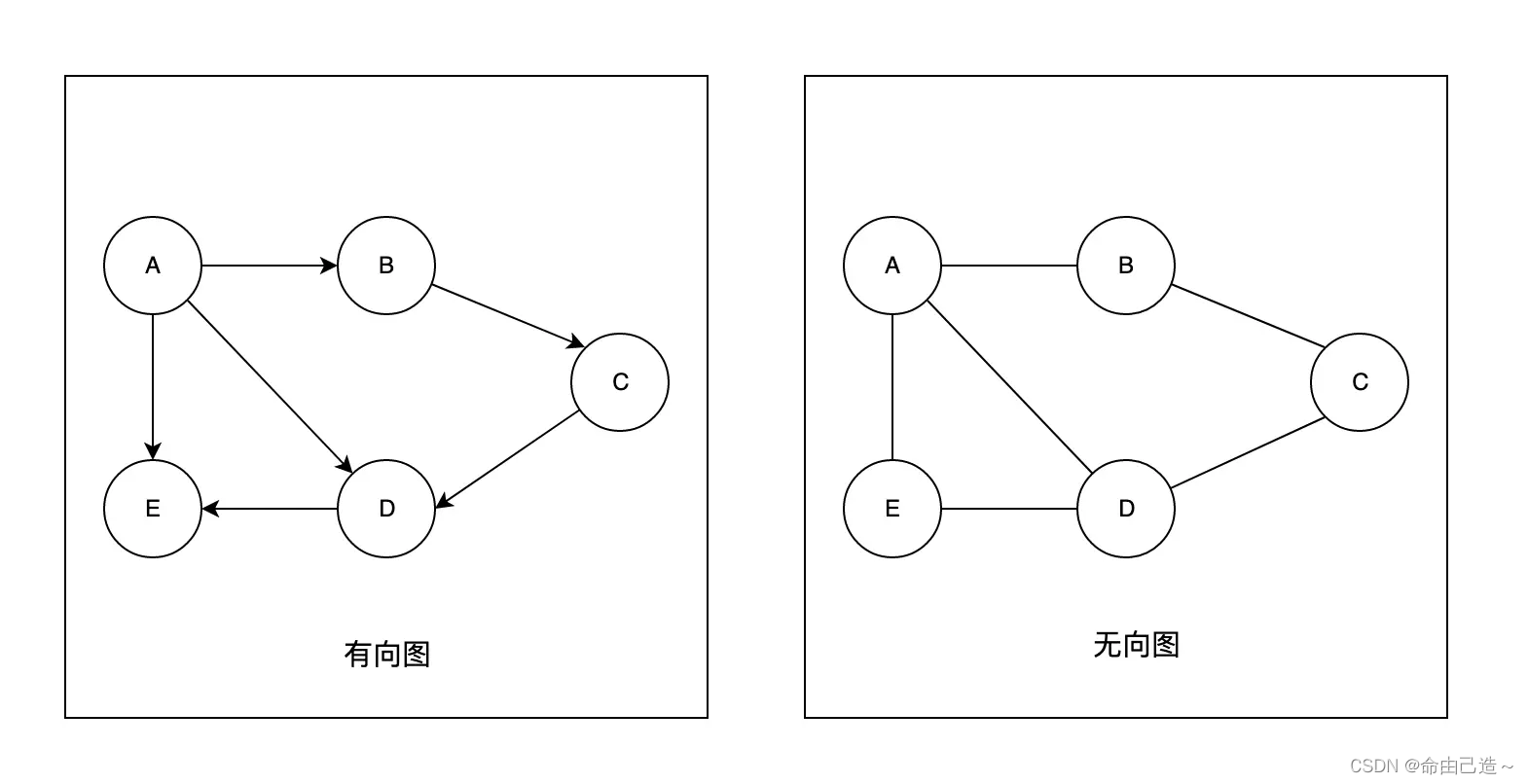
如上图所示,有向图中的边具有明确方向,例如从 A 指向 B;而无向图中的边没有方向,只表示两个顶点之间存在连接关系。
2. 图的存储方式
在计算机中存储图,常用的方式主要有两种:邻接矩阵和邻接表。二者各有优劣,适用于不同类型的图结构。
2.1 邻接矩阵
邻接矩阵使用一个 V × V 的二维数组来表示图,其中 V 是顶点数量。对于顶点 u 和顶点 v,g[u][v] 的值表示从顶点 u 到顶点 v 的边权。
若顶点之间不存在边,则通常用一个特殊值 inf 表示不可达;对于无权图,也可以用 0 表示无边,用 1 表示有边。
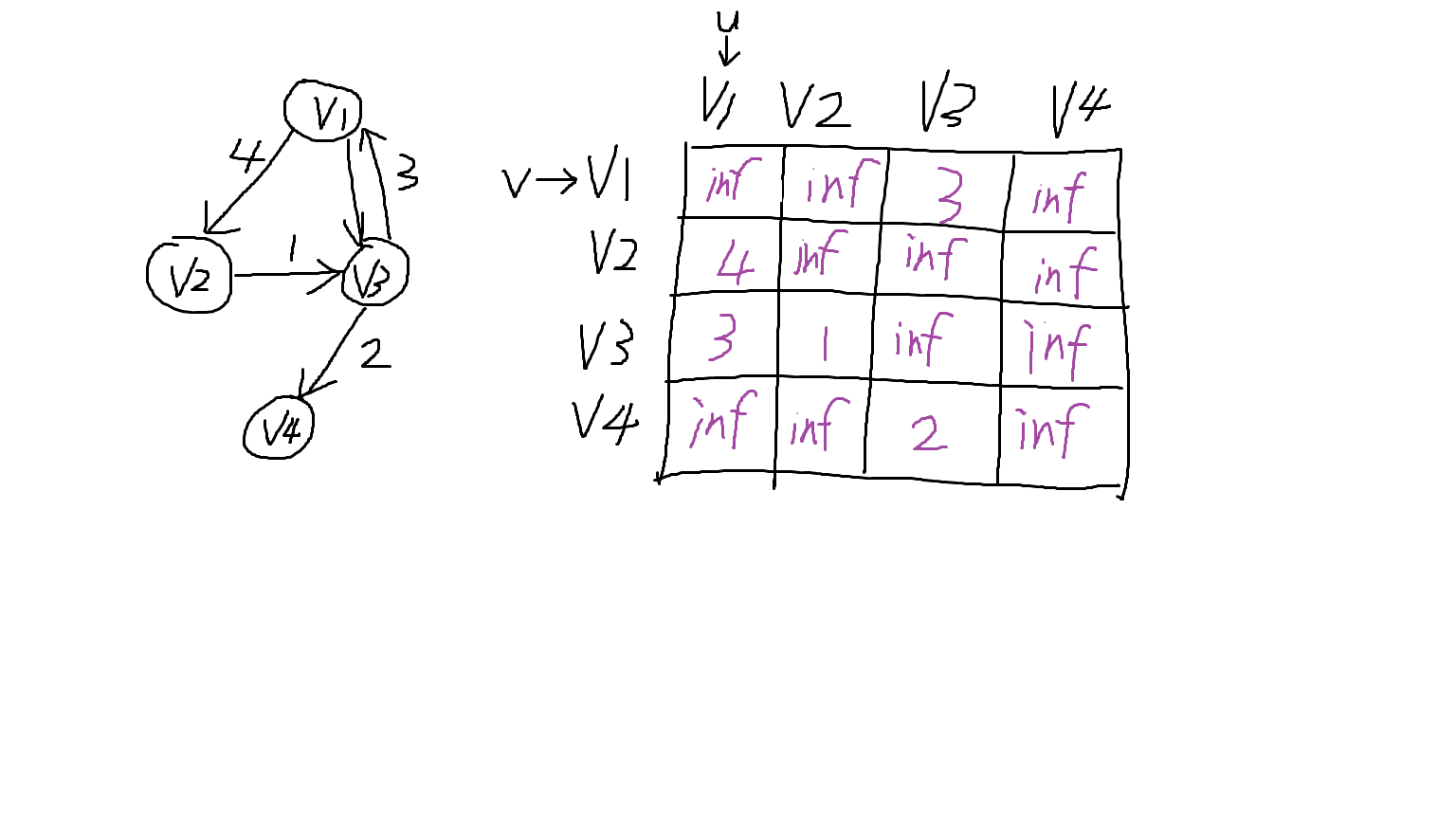
邻接矩阵的特点是查询两点之间是否存在边非常方便,时间复杂度为 O(1)。但它需要开一个 V × V 的二维数组,因此空间复杂度为 O(V²)。当图比较稠密,即边数接近顶点数平方时,邻接矩阵比较适合。
2.2 邻接表
邻接表为每个顶点维护一个链表或数组,链表中存储该顶点能够直接到达的其他顶点以及对应边权。对于每个顶点 u,邻接表中保存所有从 u 出发的边。
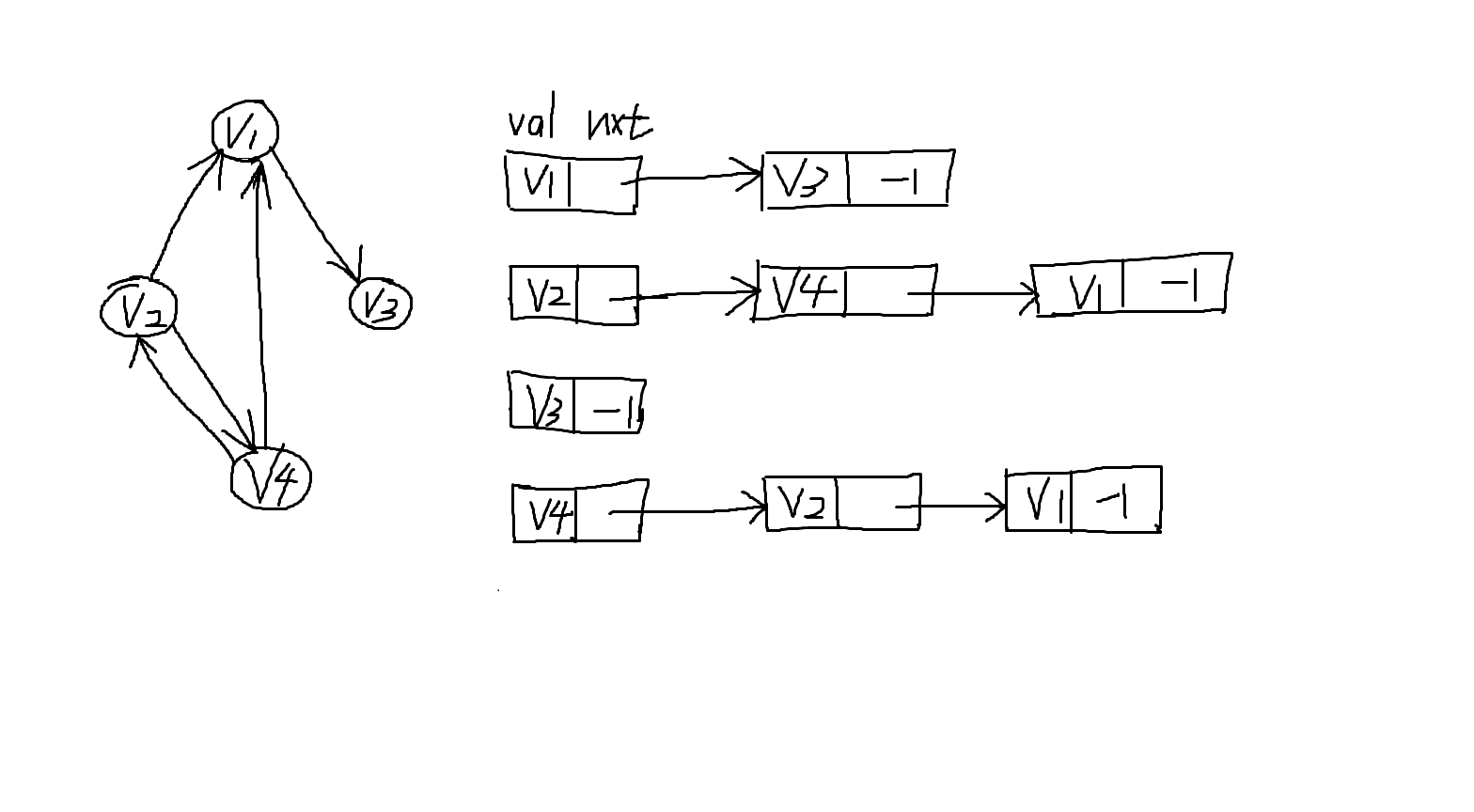
邻接表更适合存储稀疏图。所谓稀疏图,就是边数远小于顶点数平方的图。在真实的大数据场景中,例如道路网络、社交网络、通信拓扑等,大多数图结构都属于稀疏图。因此,在实现 Dijkstra 算法时,通常优先选择邻接表来存储图。
二、贪心算法思想
贪心算法是一种在每一步选择中都采取当前状态下最优选择的算法。它的基本思想是:每一步只考虑当前看起来最好的选择,并希望通过一系列局部最优选择得到整体最优解。
例如,在找零钱问题中,若纸币面值为 [1, 5, 10, 20, 50],现在需要凑出 66 元,并要求纸币张数最少。贪心策略会先选择最大面值 50,剩下 16 元;然后选择 10,剩下 6 元;再选择 5,剩下 1 元;最后选择 1。这样总共使用 4 张纸币。
这个过程体现了贪心算法的特点:每一步都选择当前能选的最大面额,从而尽量减少纸币张数。
Dijkstra 算法本质上也使用了贪心思想:每次从未确定的顶点中选出距离源点最近的顶点,并认为该顶点的最短距离已经确定,然后继续用它更新其他顶点。
三、Dijkstra 算法概述
Dijkstra 算法是一种经典的单源最短路径算法,用于在非负权图中求出从一个源点到所有其他顶点的最短路径。
算法的核心思想是维护一个距离数组 dist[],其中 dist[i] 表示从源点到顶点 i 的当前最短距离。同时使用一个标记数组 vis[],表示某个顶点的最短路径是否已经确定。
Dijkstra 算法的基本步骤如下:
- 初始化所有顶点到源点的距离为
inf,源点到自己的距离为0; - 在所有未被确定的顶点中,找到距离源点最近的顶点
t; - 将顶点
t标记为已确定; - 用顶点
t去更新所有与它相邻的顶点距离; - 重复上述过程,直到所有顶点都被处理完。
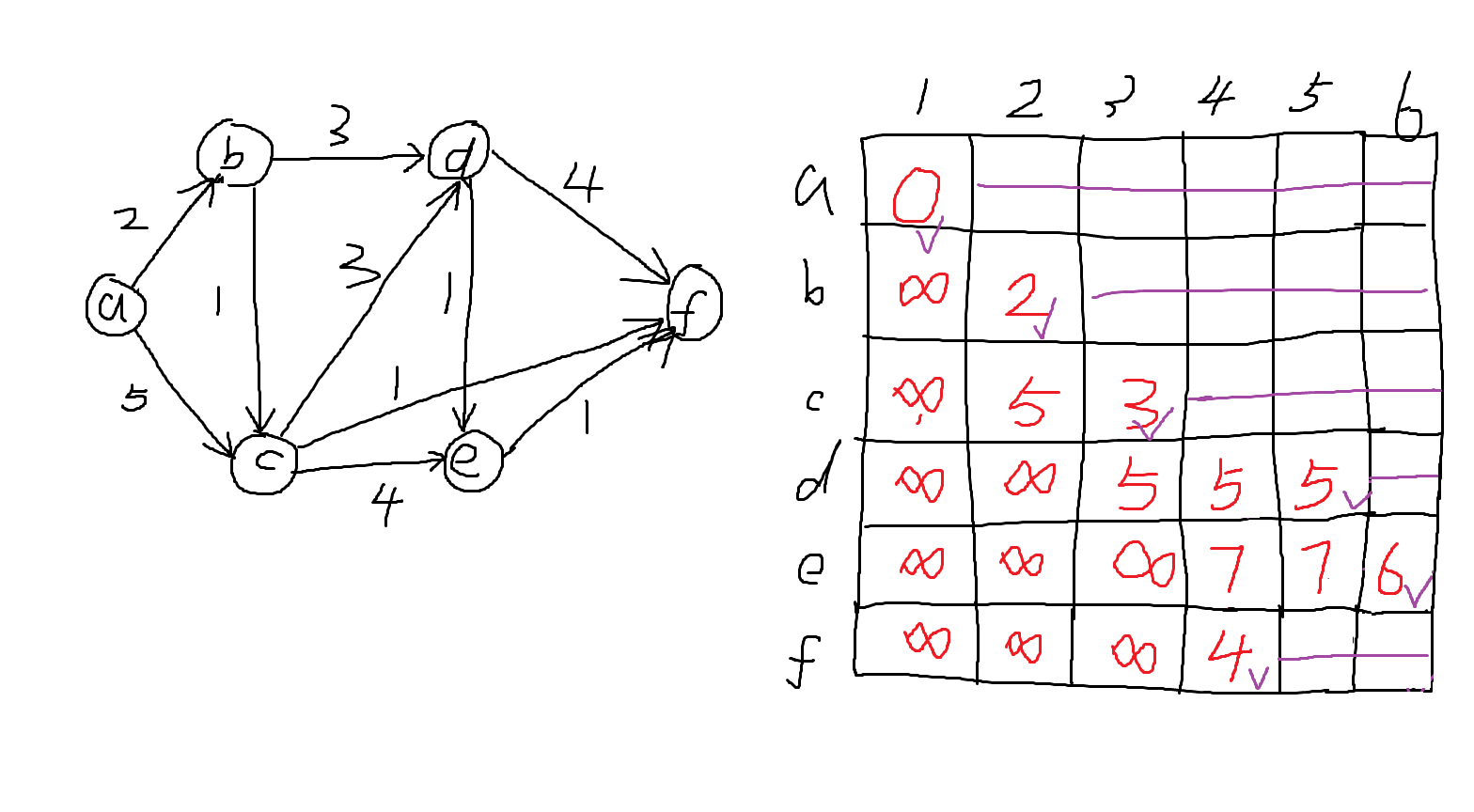
从图中可以看出,Dijkstra 算法会不断从当前可达的点中选择距离最短的点,并利用这个点继续扩展路径。这个过程类似于“从源点向外一圈一圈扩散”,每次确定一个离源点最近的顶点。
四、Dijkstra 算法代码实现
下面给出基于邻接表的朴素 Dijkstra 算法示例,适用于边权非负的有向图或无向图。
1 |
|
这段代码中,h[]、e[]、ne[]、w[] 共同构成邻接表。dist[] 用来存储源点到各个点的当前最短距离,vis[] 用来标记某个点是否已经确定最短路。
五、Dijkstra 算法时间和空间复杂度
1. 时间复杂度
朴素 Dijkstra 算法的时间复杂度主要由两部分组成:
第一部分是寻找当前距离最近的未确定节点。每一轮都需要遍历所有顶点,因此每轮耗时 O(n),总共进行 n 轮,所以这一部分时间复杂度为 O(n²)。
第二部分是松弛邻居节点。对于邻接表来说,整个算法过程中,每条边最多被遍历一次,所以松弛操作总时间复杂度为 O(m)。
因此,朴素 Dijkstra 算法的总时间复杂度通常写作:
1 | O(n² + m) |
当图比较稠密时,m 可能接近 n²,此时时间复杂度可以近似看作 O(n²)。
2. 空间复杂度
Dijkstra 算法的空间复杂度主要包括图结构存储和算法辅助数组。
邻接表需要存储所有边以及每条边的下一条边指针,因此空间复杂度为:
1 | O(n + m) |
此外,算法还需要 dist[] 距离数组和 vis[] 标记数组,这两部分空间复杂度均为 O(n)。因此整体空间复杂度可以表示为:
1 | O(n + m) |
六、Dijkstra 算法优化
朴素 Dijkstra 算法每次都要遍历所有点来寻找当前距离源点最近的点。当顶点数量很大时,这个过程会造成较高的时间开销。为了提高效率,可以使用优先队列,也就是最小堆来优化这一查找过程。
使用堆优化后,每次取出当前距离最小的点只需要 O(log n) 的时间。对于稀疏图来说,堆优化 Dijkstra 的时间复杂度通常为:
1 | O(m log n) |
堆优化 Dijkstra 算法更加适合边数较少、顶点数量较大的图结构,例如道路网络、通信网络和社交网络等。
1 |
|
七、最短路算法在大数据中的应用
随着大数据时代的到来,复杂网络关系的分析变得越来越重要。最短路算法作为图论中的经典算法,能够在大规模网络数据中寻找较优路径,因此在多个大数据应用场景中发挥着重要作用。
1. 网络路由与通信优化
在互联网、物联网等大规模通信网络中,Dijkstra 算法可用于计算节点之间的最短通信路径。通过计算最短路径,可以减少数据传输延迟,提高通信效率。在软件定义网络(SDN)中,系统还可以结合实时流量数据动态调整路由策略,从而优化整体网络性能。
2. 交通与物流路径规划
在智慧交通和物流配送系统中,Dijkstra 算法可用于计算最短或最快行驶路径。结合实时交通数据、天气数据和历史拥堵数据,系统能够为车辆规划更合理的路线,从而提高运输效率并降低物流成本。
3. 社交网络与推荐系统
在社交网络中,最短路径可以用来衡量用户之间的关系距离。例如,两个用户之间经过的人越少,说明他们之间的关系可能越紧密。在推荐系统中,也可以将用户、商品、标签等看作图中的节点,通过计算图中路径关系,提高推荐结果的准确性和多样性。
八、总结
Dijkstra 算法是一种经典的单源最短路径算法,具有思想清晰、实现稳定、应用广泛等特点。它通过贪心策略逐步确定源点到各个顶点的最短距离,适用于所有边权非负的图。
在实际应用中,如果图规模较小或较稠密,可以使用朴素 Dijkstra 算法;如果图规模较大且较稀疏,则更推荐使用基于优先队列的堆优化 Dijkstra 算法。在大数据与复杂网络环境下,Dijkstra 算法可以广泛应用于网络路由、智慧交通、物流配送、社交网络分析和推荐系统等领域。
参考文献
[1] 徐鹏. Dijkstra 算法在 GIS 路径规划中的优化与应用[D]. 南京: 南京师范大学, 2021.
[2] 李晓明. 电力通信网路由优化的 Dijkstra 改进算法研究[D]. 武汉: 华中科技大学, 2023.
[3] 王浩宇. 物流配送路径优化的多约束 Dijkstra 算法研究[D]. 广州: 华南理工大学, 2022.
附件下载
本文 PDF 版本可点击下载: